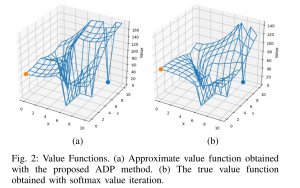
This objective is to develop a model-free reinforcement learning method for stochastic planning under temporal logic constraints. In recent work [1], we propose an approach to translate high-level system specifications expressed by a subclass of Probabilistic Computational Tree Logic (PCTL) into chance constraints. We devise a variant of Approximate Dynamic Programming method—approximate value iteration— to solve for the optimal policy while the satisfaction of the PCTL formula is guaranteed.
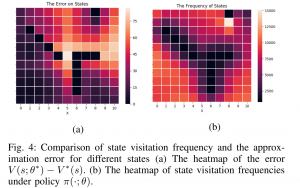
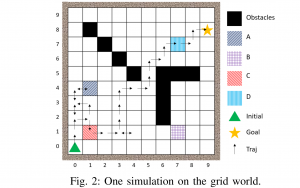
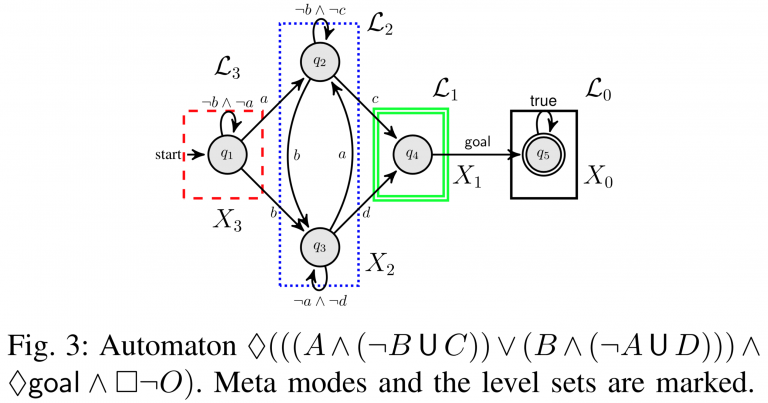
In [2], we study model-free reinforcement learning to maximize the probability of satisfying high-level system specifications expressed in a subclass of temporal logic formulas—syntactically co- safe linear temporal logic. In order to address the issue of sparse reward given by satisfaction of temporal logic formula, we propose a topological approximate dynamic programming which includes two steps: First, we decompose the planning problem into a sequence of sub-problems based on the topological property of the task automaton which is translated from a temporal logic formula. Second, we extend a model-free approximate dynamic programming method to solve value functions, one for each state in the task automaton, in an order reverse to the causal dependency. Particularly, we show that the run-time of the proposed algorithm does not grow exponentially with the size of specifications. The correctness and efficiency of the algorithm are demonstrated using a robotic motion planning example.
Li, L., & Fu, J. (2019). Topological approximate dynamic programming under temporal logic constraints. 2019 IEEE 58th Conference on Decision and Control (CDC), 5330–5337.
Li, L., & Fu, J. (2019). Approximate dynamic programming with probabilistic temporal logic constraints. 2019 American Control Conference (ACC), 1696–1703.